
Unsupervised machine learning is an important type of machine learning which does not require labelled data. This means the model does not know the desired output for any given input. Instead, the model must learn to identify patterns in the data independently. This type of unsupervised learning is often used for many tasks, such as clustering, dimensionality reduction, and anomaly detection.
Clustering which groups data points generally based on their similarity. This can generally be useful for many tasks, such as customer segmentation, where customers are grouped based on their buying habits, or fraud detection, where anomalous data points are identified.
Dimensionality reduction is unsupervised learning algorithm that reduces the number of features in a dataset while preserving as much information as possible. This can be useful for tasks such as visualization, where a high-dimensional dataset is reduced to a lower dimension to be easily plotted, or data compression, where a dataset is compressed to save space.
Anomaly detection is a type of unsupervised machine learning that identifies data points significantly different from the rest of the data. This can be useful for tasks such as identifying errors in a dataset. To gain more detailed information about unsupervised machine learning, Join Data Science Courses in Chennai at FITA Academy, where our professional trainers will train you with the real-time application.
Why Use Unsupervised Learning?
- It can identify underlying patterns and structures in the data. This generally helps to uncover hidden insights and relationships in the data.
- It can enable the clustering of similar data points. This can be used for tasks such as data grouping or customer segmentation.
- Some of the application of unsupervised learning includes natural language processing, image and video analysis, anomaly detection, customer segmentation, and recommendation engines.
- It can detect anomalies or outliers in data. This can be used for fraud detection and fault monitoring.
- It reduces the dimensionality of high-dimensional data. This can simplify analysis and visualization.
- It can be a preprocessing step to improve supervised learning models by extracting features or identifying clusters.
- It can uncover novel insights and relationships in the data. This can help to gain a better understanding of the data.
- It can reduce human bias as it does not rely on human annotations.
- It is scalable and applicable to large-scale datasets.
- It is widely used in various domains, including finance, marketing, healthcare, natural language processing, and computer vision.
Working of Unsupervised Learning
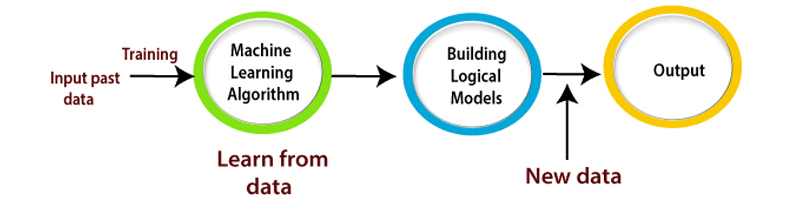
The unsupervised learning algorithms work with unlabeled data to discover patterns, structures, or relationships within the dataset. This type of machine learning is often used when labelled data is scarce or costly or when the goal is to learn about the data without prejudgement concepts. Unsupervised learning begins with the algorithm receiving a dataset containing multiple examples, each with various features or attributes. The algorithm then explores the data to identify similar underlying patterns and relationships among the data points.
One of the primary tasks of unsupervised learning is clustering, where the algorithm groups similar data points into clusters based on their feature similarity. Additionally, unsupervised learning may involve dimensionality reduction techniques to reduce the number of features in the given dataset while retaining essential information. Anomaly detection is another crucial aspect of unsupervised learning, where the algorithm identifies data points that significantly deviate from the norm, indicating anomalies or outliers.
The results of unsupervised learning can provide valuable insights into the data distribution and can be used for data exploration, segmentation, anomaly detection, and other tasks. To practice all these data distributions with an example under the guidance of professionals, Join Data Science Courses in Bangalore. Unlike supervised learning, there are no explicit labels for evaluation, so performance is often assessed qualitatively, through visualization, or using domain-specific measures.
Problems of Unsupervised Machine Learning Algorithm
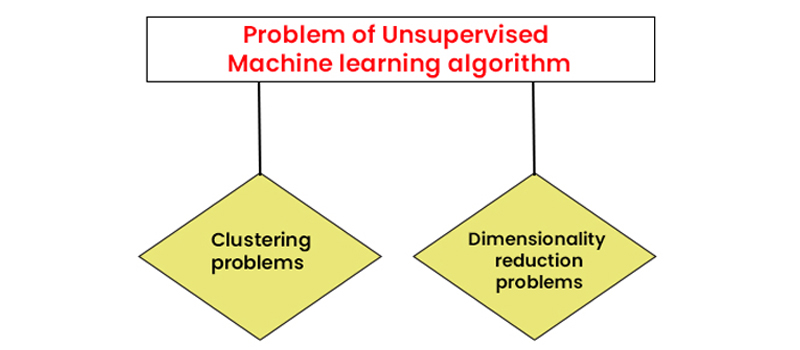
The types of unsupervised learning algorithms based on the tasks they aim to address:
Clustering Problems
Clustering algorithms group similar data points based on their feature similarities or distances. The primary goal is to partition the data into clusters so that data points within the same cluster are more similar than those in other clusters. Clustering is an essential task in unsupervised learning and finds applications in various fields, such as customer segmentation, image segmentation, and data categorisation.
Dimensionality Reduction Problems
Dimensionality reduction algorithms focus on reducing the number of features or variables in the data while preserving the essential information. The high dimensionality of data can lead to computational complexity and difficulty in visualization. Dimensionality reduction techniques help compel the data into a lower-dimensional space, making it more manageable and interpretable. These techniques are often used for visualization, feature extraction, and data preprocessing before applying other machine-learning algorithms.
To overcome all these Unsupervised Machine Learning Algorithms problems when implementing real-time projects, Join Data Science Course in Pondicherry to get trained by our professional trainers.
Unsupervised Machine Learning Algorithm
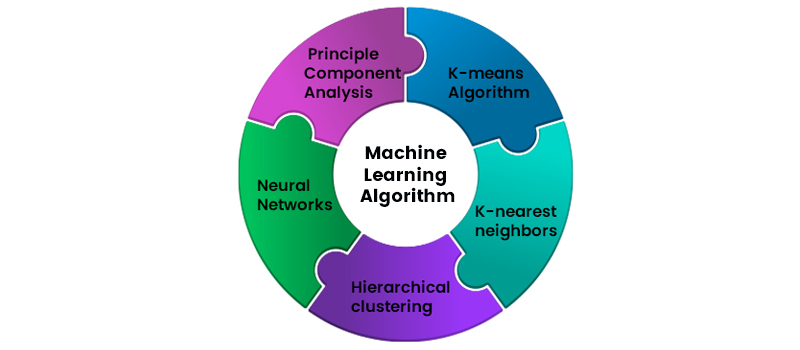
The unsupervised classification algorithm can be classified into different types:
K-means Algorithm
K-means clustering groups data points into K-distinct clusters. The algorithm works by iteratively partitioning the data into clusters, representing each cluster by its centroid. Initially, K centroids are randomly chosen or can be based on some heuristics. Each iteration assigns data points to the nearest centroid for forming clusters. Then the centroids are updated by computing the mean of the data points in each cluster. This process generally continues until convergence, where the centroid stabilizes or a predetermined number of iterations is reached.
The K-means algorithm aims to minimize the within-cluster sum of squares, making the data points where each cluster is as similar to their centroid as possible. It is usually sensitive to the initial centroid placement, which requires the user to specify the number of clusters.
K-nearest neighbors
K-nearest neighbors (KNN) is a simple and versatile unsupervised learning algorithm which generally used for classification and regression tasks. KNN works by finding the K nearest neighbors of a new data point in the feature space and then predicting the label or value of the new data point based on the labels or values of its neighbors. KNN is a non-parametric algorithm that makes no assumptions about the data distribution. However, KNN can be computationally expensive, especially with large datasets.
Hierarchical Clustering
Hierarchical clustering is unsupervised learning algorithm that groups data points into clusters generally based on their similarity. There are two important types of hierarchical clustering: agglomerative and divisive. Each data point is initially treated as a separate cluster in agglomerative clustering. The algorithm then merges the closest clusters where all the data points belong to a single cluster. The choice of similarity metric and linkage method impacts the clustering results.
In divisive clustering, all data points start in a single cluster. The algorithm then recursively splits the cluster into smaller clusters until each data point is its own. The choice of similarity metric and linkage method also impacts the clustering results. Hierarchical clustering can be used to visualize and interpret complex datasets. It can also be used to identify outliers and find data patterns.
Neural Networks
Neural networks are an important unsupervised learning algorithm inspired by the human brain, composed of artificial neurons that process input data, apply weights and produce an output using activation functions. Data flows through layers of neurons, including input, hidden, and output layers. Trainers at FITA Academy provide information about neural networks that occur through backpropagation, which optimizes the network weights using gradient descent in the Data Science Course in Trichy.
Popular architectures of neural networks include:
- Feedforward neural networks.
- Convolutional neural networks (CNNs) for image analysis.
- Recurrent neural networks (RNNs) for sequential data.
- Generative adversarial networks (GANs) for data generation.
Principle Component Analysis
Principle Component Analysis (PCA) is generally a dimensionality reduction technique that transforms high-dimensional data into a lower-dimensional space while preserving the essential information. It works by finding linear combinations of the original features, called principal components, that capture the maximum variance in the data. PCA finds applications in data compression, visualization, and noise reduction.
Advantages of Unsupervised Machine Learning
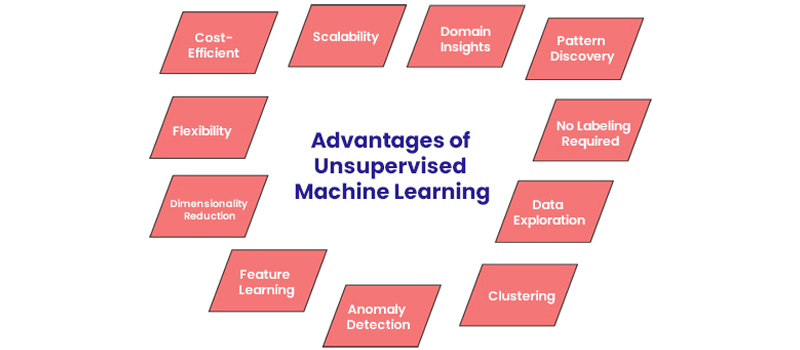
- Pattern Discovery: Unsupervised learning helps discover hidden patterns and relationships within data.
- No Labeling Required: It doesn't need labelled data, saving time and effort in data annotation.
- Data Exploration: Useful for exploring and understanding data before more specific analyses.
- Clustering: Groups similar data points together, aiding in data segmentation.
- Anomaly Detection: Identifies unusual data points that might indicate anomalies or errors.
- Feature Learning: Automatically learns valuable features for downstream tasks.
- Dimensionality Reduction: Reduces data complexity while retaining essential information.
- Flexibility: Applicable to various data types and domains.
- Cost-Efficient: Eliminates the need for manual labeling, reducing costs.
- Scalability: Handles large datasets and reveals insights that might be missed manually.
- Domain Insights: Provides domain-specific insights and knowledge.
Unsupervised machine learning is the best tool for exploring and understanding complex datasets without labelled examples. It can discover hidden patterns, structures, and relationships in the data and identify anomalies and fraud. Unsupervised learning is beneficial when labelled data is scarce or unavailable. By leveraging unsupervised machine learning, data scientists can unlock the potential of vast and diverse datasets, allowing data-driven decision-making and innovation. Join Data Science Course in Coimbatore to know more detailed information about unsupervised learning algorithms from our expert trainers.